
This is part 1 in a multi-part series where I ultimately want to see what sort of components are present in YouTube videos that perform relatively well, specifically in the tech/swe space. Before I get into the analysis, I need to gather data and process it into a dataset in a process known as extract, transform and load (ETL). In this post, I will focus on gathering the data required to begin exploring this question in more depth; essentially, the 'E' in ETL. The subsequent post in the series will focus on the rest of the ETL process.
For extracting the data I'll need, I'm going to work with the YouTube Data API (v3). You can find more details at the official documentation. I'll be using the python client to interact with the API, but I won't be spending a lot of time explaining how to get up and running with the client; instead, I'll refer you to Corey Schafer's YouTube video on the setup if you want to follow along. There are also a ton of guides and resources that are a quick Google search away!
I should also note that for this post, I will be walking through the entire process of building the dataset from the ground up. This means code will be changing and there will be refactoring that happens. My goal in doing so is to best mimic the process of actually using an unfamiliar API for the first time, which I'm hopeful will be a value-add for newbies that stumble across this article and want to get started with some analysis using this data.
Overview
Here is a diagram that overviews how the data collection script will work:
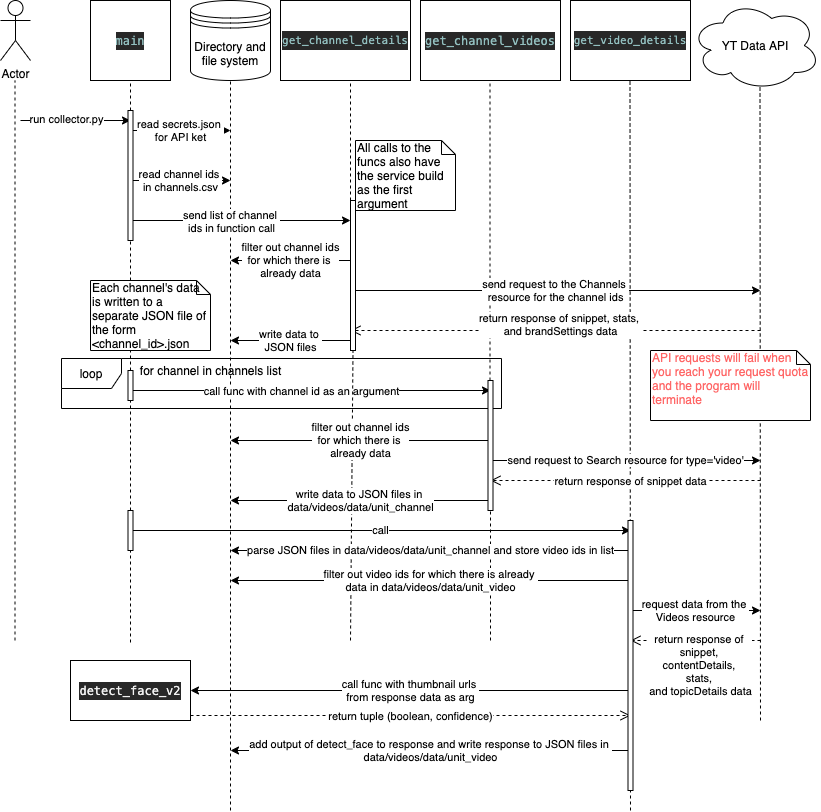
The diagram is meant to be read top down, left to right. It is not comprehensive of all the inner workings of the script, but definitely encompasses the gist of what's going on. There are three main functions that I'll be using, each corresponding to a different resource in the YouTube Data API:
- get_channel_details,
- get_channel_videos,
- get_video_details.
These functions make use of the Channels, Search, and Videos resources, respectively. A resource is basically just an API endpoint. The YouTube Data API exposes a lot of endpoints and there are a lot of resource methods so it's easy to get lost. To navigate this data jungle, I need to be pretty clear on what data I want. Broadly speaking, I want data that pertains to YouTube videos for a number of channels that I've picked. As mentioned, the resources that I'll be using to get this data are the Channels, Search, and Videos resources.
Getting Started with the API
The directory structure at this point in time looks like this:
yt_content_analysis/ ├── pyt_env/ ├── secrets.json └── collector.py
where pyt_env is a virtual environment and secrets.json is where I'm keeping the API key - the contents of which look like:
{
"API_KEY": "<your-key-here>"
}
First, let's get up and running with the API by sending a request for some data to a resource and printing the output to the console. I'm going to use the Search resource with the python client to get video data for a random channel I've picked:
import json
from googleapiclient.discovery import build # python client
with open('secrets.json', 'r') as key:
secrets = json.load(key)
API_KEY = secrets['API_KEY']
API_SERVICE_NAME = 'youtube'
API_VERSION = 'v3'
service = build(API_SERVICE_NAME, API_VERSION, developerKey=API_KEY)
request = service.search().list(
part='snippet',
channelId='UCfzlCWGWYyIQ0aLC5w48gBQ',
type='video'
)
result = request.execute()
print(result)
Which should print a dict of data for the videos beloning to the channel id. This is a good start, but there are a few caveats that need to be considered, which are handled below.
Get Channel Videos
Firstly, the API limits results in the response to 50 video objects (default is 5). Beyond this, we must page through the response (the response object is paginated). Even then, the maximum size of a response object is 500 results, so we need to deal with this as well. One way of doing this is to limit the response by year created and loop through years. I'm first going to take care of paging for the Search resource, then I'll work my way up into dividing the paging functionality into a function that can be used for different resources. Lastly, I will take care of the 500 results contrainst.
def get_channel_videos(service, channel_id, part='snippet', type='video', results=50):
yt_search = service.search()
request = yt_search.list(part=part, channelId=channel_id,
type=type, maxResults=results)
response = request.execute()
output = response
while response['items']:
previous_request = request
previous_response = response
request = yt_search.list_next(previous_request=previous_request,
previous_response=previous_response)
response = request.execute()
# add the items from the response to the items list
output['items'].extend(response['items'])
with open('out.json', 'a+') as video_data:
response_obj = json.dumps(output)
video_data.write(response_obj)
I'll be using the convention of sticking the function calls and other non-functional code in a main() function:
def main():
with open('secrets.json', 'r') as key:
secrets = json.load(key)
API_KEY = secrets['API_KEY']
API_SERVICE_NAME = 'youtube'
API_VERSION = 'v3'
service = build(API_SERVICE_NAME, API_VERSION, developerKey=API_KEY)
channels = ['UCfzlCWGWYyIQ0aLC5w48gBQ'] # sentdex
for channel in channels:
get_channel_videos(service, channel)
if __name__ == "__main__":
main()
What I've done above is essentially the same as the first block of code I showed, except that I've modularized the logic into functions and added paging to the request. I also am now using the maxResults argument so that the API returns 50 results per page in the response object (dict) instead of the default 5. The while loop in the part where I'm paging through the response.
Essentially, I check that the 'items' key (corresponding value is a list) in the response dict is non-empty. While it is non-empty, send a request to the Search resource with the previous request and response as arguments to the list_next resource method. list_next pages through the response using tokenPagination key in the response dict. For more details, check out the python client documentation on these two methods.
The get_channel_details function appends data to the 'items' list in every iteration of the while loop. It then writes this object to a JSON file called out.json in the root directory of the project. If you open this file, you should notice that the items list will not have more than 500 objects. I'll address this problem next.
First, I want to modularize pagining into a function named page_through_response. I will also want to add the ability to get >500 results by looping over years.
def page_through_response(service_instance, request, response) -> dict:
"""
Pages through a response by calling on the list_next method of the service instance.
Returns the full response dictionary.
"""
output = response
while response['items'] and len(response['items']) >= 50:
previous_request = request
previous_response = response
request = service_instance.list_next(previous_request=previous_request,
previous_response=previous_response)
try:
response = request.execute()
except AttributeError:
break
# add the items from the response to output
output['items'].extend(response['items'])
return output
This function just encapsulates the logic I was using in get_channel_videos to page through the response. I now need to update get_channel_videos to loop over years so that I can get >500 results.
def get_channel_videos(service, channel_id, part='snippet', type='video', results=50):
yt_search = service.search()
final_out = {}
for year in range(2000, datetime.today().year+1):
start = datetime(year, 1, 1)
end = start + relativedelta(years=1)
# prepare dates in a format the YT API is happy with
start, end = [date.isoformat('T')+'Z' for date in [start, end]]
request = yt_search.list(part=part,
channelId=channel_id,
type=type,
publishedAfter=start,
publishedBefore=end,
maxResults=results
)
response = request.execute()
# full response output for the year
data_out = page_through_response(yt_search, request, response)
# build on the items list in the final_out dict to form the complete response
if final_out:
final_out['items'].extend(data_out['items'])
else:
final_out = data_out
with open('out1.json', 'a+') as video_data:
response_obj = json.dumps(final_out)
video_data.write(response_obj)
I am now looping through years (see arguments to the list method) and able to get the full result set of video data for the channel, which I write to out1.json. The publishedAfter and publishedBefore parameters in this instance will filter out videos that were not published within the specified timeframe.
However, a major contraint of the Search resource is that it uses an immense amount of quota for the API - you cannot make more than 100 requests to this resource in a 24 hour period, and that includes every page-through request. In light of this, it's very inefficient to use an arbitrary year to begin requests from as I have done in the above code (I start at 2000). It would instead make more sense to get channel data, which includes when the channel was published, and start from there (you can't publish a video before you've created the channel, after all). Requests to the Channels resource take up much less quota.
Get Channel Details
At this point, I'm going to create a few additional folders. I also need to create a csv of channel ids for which I want data and read those ids into a list within the main function. The process of getting channel ids was manual - I hand-picked a few of interest. The project directory now looks like this:
yt_content_analysis/
├── pyt_env/
├── data/
├── channels/
└── videos/
└── data/
├── unit_channel/
└── unit_video/
├── channels.csv
├── secrets.json
└── collector.py
Up until now, for get_channel_videos I have just been writing the output to a json file in the project root dir as out1.json. I obviously want data for multiple channels and videos, so adjustments will have to be made to that function as well. First, though, I am going to create the get_channel_details func and a few helper funcs along with it.
I'm going to be writing channel data to JSON files in data/channels, with each file named after the video channel id. Since there is a quota limit, I will have to run the script multiple times, and I don't want to just overwrite the channel data - that's inefficient and a waste of request quota. Instead, I'll filter out channel ids by reading filenames from data/channels and removing these ids from the channel id list. To do that, I'll use a helper function called filter_channel_or_video (I'm going to filter video data in the same way eventually).
def filter_channel_or_video(ids: list, path: str) -> list:
"""
Checks if there exists data for the provided channel or video ids in the
directory (path arg), assuming the directory contains files of format
<id<.<ext>
Args:
- ids: a list of channel or video ids
- path: path to the directory to check
Returns a filtered list of ids that were not found in the directory.
"""
all_files = os.listdir(path)
# remove the file extension for the files in the dir
all_files = [
os.path.splitext(file_id)[0] for file_id in all_files
]
# create a copy of the list to avoid mutating the original
filtered = ids.copy()
to_remove = []
# do a lookup of the id in the directory to see if a file already exists
for file_id in filtered:
if file_id in all_files:
to_remove.append(file_id)
# remove the id from the list
[filtered.remove(id) for id in to_remove]
return filtered
Now, for the get_channel_details func.
def get_channel_details(service, channels: list, part='snippet,statistics,brandingSettings', results=50):
"""
Makes use of the channel resource list method. Gets channel data for
resource properties defined in the part argument and writes the repsonse
to JSON files in data/channels
Args:
- service: The YouTube Data API service
- channel_ids: A comma-separated string of the YouTube channel ID(s)
- part: A comma-separated string of channel resource properties
- results: Max results returned in the reponse
"""
channel_detail = service.channels()
channels_path = 'data/channels/'
# get list of channels for which there is no data in the channels_path dir
channels_list = filter_channel_or_video(channels, channels_path)
if channels_list:
# take list of filtered channel ids -> string of comma-separated ids
channel_ids = ",".join(channels_list)
# make the request to the resource
request = channel_detail.list(
part=part, id=channel_ids, maxResults=results
)
response = request.execute()
response_items = response['items']
# want to write a folder with the channel id to channels_path
# that holds .json files of the response for each channel id
for channel in response_items: # channel is a dict of channel data
with open(channels_path+'{}.json'.format(channel['id']), 'w+') as channel_data:
response_obj = json.dumps(channel)
channel_data.write(response_obj)
For the Channels resource list method, the channels are passed in as a string of comma-separated channel ids.
This should do. Now I just need to polish up the get_channel_videos func and create get_video_details. Before I do that, though, I should call out the changes in the main func, where I'm now reading channel ids from the csv and making calls to the functions I've defined so far in the script.
def main():
# ... truncated ...
service = build(API_SERVICE_NAME, API_VERSION, developerKey=API_KEY)
# read channel ids from file
with open('channels.csv', 'r') as f:
csv_reader = reader(f)
next(csv_reader) # skip header
rows = list(csv_reader)
# store channel ids in a list
channels = [row[0] for row in rows]
# write channel detail info
get_channel_details(service, channels)
for channel in channels:
# write channel video data
get_channel_videos(service, channel)
Note that the code has been truncated so that I'm not repeating myself.
Adjustments to get_channel_videos
In the last get_channel_videos func, I successfully set up paging through the response and I am sending requests that filter for videos published within a time frame of one year, starting from 2000, and iterating up until the present year. I want to instead get the value of the publishedAt key of the channel object in order to start at this date. I'll first set up a basic helper func to read values for a provided key in the JSON file.
def get_response_item(resource_property: str, key: str, channel_id: str, path: str, ext='.json'):
"""
Get the value for the key in the resource_property dict for the provided
channel_id and path.
Args:
- resource_property: a key in the response dict corresponding to the resource property ('part') to search
- key: key to search for in the resource_property dict
- channel_id: channel id
- path: directory to search; must end with trailing /
"""
with open(path+channel_id+ext) as response:
data = json.load(response)
item = data[resource_property][key]
return item
Onto the final form of the get_channel_videos function:
def get_channel_videos(service, channel_id: str, part='snippet', type='video', results=50):
"""
Get video data associated with a channel id and write the response to a JSON
file in data/videos.
"""
yt_search = service.search()
channel_videos_path = 'data/videos/data/unit_channel/'
channels_path = 'data/channels/'
channel = filter_channel_or_video([channel_id], channel_videos_path)
final_out = {}
if channel:
# how many videos the channel has
video_ct = get_response_item(
'statistics', 'videoCount', channel_id, channels_path
)
# the date the channel was created
year_pub = get_response_item(
'snippet', 'publishedAt', channel_id, channels_path
)
year_pub = datetime.strptime(year_pub, "%Y-%m-%dT%H:%M:%S%z").year
if int(video_ct) > 500:
for year in range(year_pub, datetime.today().year+1):
start = datetime(year, 1, 1)
end = start + relativedelta(years=1)
# prepare dates in a format the YT API is happy with
start, end = [date.isoformat('T')+'Z' for date in [start, end]]
request = yt_search.list(part=part,
channelId=channel_id,
type=type,
publishedAfter=start,
publishedBefore=end,
maxResults=results
)
response = request.execute()
# full response output for the year
data_out = page_through_response(
yt_search, request, response
)
# build on the items list in the final_out dict to form the complete response
if final_out:
final_out['items'].extend(data_out['items'])
else:
final_out = data_out
else:
request = yt_search.list(part=part,
channelId=channel_id,
type=type,
maxResults=results
)
response = request.execute()
# full response output for the year
data_out = page_through_response(yt_search, request, response)
final_out = data_out
with open(channel_videos_path+'{}.json'.format(channel_id), 'w+') as video_data:
response_obj = json.dumps(final_out)
video_data.write(response_obj)
At this point, I am getting channel data (using the Channels resource) and data for all the videos belonging to those channels (using the Search resource). However, the Search resource doesn't provide me with all the data I want for the channels. It's a good start and necessary because I now have a lot of video ids and other metadata, but I want statistics on view count, likes, dislikes, playback duration, etc. In order to get all that data, I need to use the Videos resource.
Get Video Details
The following function is the culmination of efforts made up until this point, and it relies on the others successfully writing data to the appropriate locations because the Videos resource requires video ids as an argument. It will first parse the JSON files in data/videos/data/unit_channel/ and appends the video ids to a list. It then relies on the filter_channel_or_video function to filter that list. Finally, it sends the requests to the Videos resource for the filtered video ids.
def get_video_details(service, part='snippet,contentDetails,statistics,topicDetails', results=50):
"""
Loop through files in data/videos/unit_channel to get the videoId inside of each objects
in the items list. Use this id to request data from the videos resource to get statistics
on each video.
"""
channel_videos_path = 'data/videos/data/unit_channel/'
videos_path = 'data/videos/data/unit_video/'
video_ids = []
# parse through json files to get all video ids
with os.scandir(channel_videos_path) as channel_vids:
for channel in channel_vids:
with open(channel, 'r') as videos:
response = json.load(videos)
for item in response['items']:
video_ids.append(item['id']['videoId'])
# filter out videos for which there is data in the folder already
videos = filter_channel_or_video(video_ids, videos_path)
video_detail = service.videos()
for i in range(0, len(videos), results):
sub_list = videos[i:i+results]
videos_str = ",".join(sub_list)
request = video_detail.list(
part=part, id=videos_str, maxResults=results
)
response = request.execute()
for item in response['items']:
# determine if the thumbnail has a person in it
try:
img = item['snippet']['thumbnails']['standard']['url']
except KeyError:
img = item['snippet']['thumbnails']['high']['url']
has_face = detect_face_v2(img)
# add has_face and the confidence as keys to the response dict
item['has_face'] = has_face[0]
item['detection_confidence'] = None
if item['has_face']:
item['detection_confidence'] = has_face[1][0]['confidence']
# write the response for the video to a file
with open(videos_path+'{}.json'.format(item['id']), 'w+') as video_data:
response_obj = json.dumps(item)
video_data.write(response_obj)
You may notice I am also doing something else in this function that I didn't mention in the workflow above. I am calling the detect_face_v2 function from my detect_face module. I won't go over that module here, but everything is available on GitHub. The function just detects whether or not a person's face is in the thumbnail of the provided video. It uses a pre-trained CNN to accomplish this feat. I add the boolean outcome and confidence of the determination to the dict and then write its contents to a JSON file in data/videos/data/unit_video/.
Wrapping Up
All that's really left is to add the function call get_video_details(service) to the end of main(). I also set up some logging in the final product. The script takes some time to run and has to be run a few times because of quoata limitations. In the end, I got about 13,000 files of video data. In the next post, I'll be walking through shaping all these JSON files into a workable dataset for use in the final analysis.
If you want to get up-and-running with the code, you can clone this project at the github repository where it's hosted.
That's it for this blog post - thanks for reading. Be sure to check out some of the other posts and leave a comment if you have something to say!
